The list of Nodes
In this post i will explain each node available in IIB/ACE/CP4I and will explain the purpose of each node.
A detailed description of each node can be found here –> https://www.ibm.com/docs/en/app-connect/11.0.0?topic=development-built-in-nodes
Nodes have INPUT TERMINALS and OUTPUT TERMINALS to allow message to pass trhoug nodes and be processed.
Some nodes have fixed input/output terminal. But other nodes can be customized with custom input/output terminals. To link a node to another, we stick the output terminal of a node to an input terminal of the next node, this is how flows are developed.
I will browse each node group and will describe all the nodes one by one.
Every node with a green line drawed on the left of the icon is called an entry node, it is a starting point node.
Every node with a blue line drawed on the rightof the icon is called an exitnode, it is an ending point node.
To link nodes between each other, the nodes will have terminals to make the connection, some nodes will have static terminal like out, failure, error terminals. And other node can have static and custom dynamic terminals.
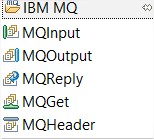
- IBM MQ group:
- MQ Input will read any incoming message entering in the queue.
- MQ Output will write the output message in the target queue.
- MQReply is similar to MQ Output but can reply to the replyToQueue name.
- MQGet will read only one message, the read will often be based on messageID or correlation ID.
- MQHeader has 4 different options, forward the header, add an MQ Header, remove an MQHeader and update MQHeader values.
- MQ Connections can made by 3 different ways, local queue manager (it will use a local bind to find the queue manager), MQ client connection properties (the connection can be static or linked with an MQ Policy), a secured connection based on a CCDTable.
- MQ Input, Output and MQReply can transactionnal and the choice is very important, espacially for error management.
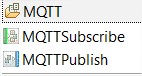
- MQTT group:
- MQTT is a lighweight Queue manager designed to send minimal reduces message for IOT devices based on topics.
- MQTTSubscribe will listen a topic based on the topic name and a host and port.
- MQTTPublish will write the message to a topic based on the topic name and a host and a port.

- Kafka group:
- Kafka Consumer will listen to a topic based on a topic name and a list of kafka brokers and a consumer group id (Consumer groups will be describes in the Kafka with a Java example).
- Kafka Producer will write to a topic based on a topic name and a list of kafka brokers.
- Kakfa read can be compare to MQGet. It will only read one message from a topic based on a topic name, a list of kafka brokers, the partition number and the offset number (similar the an index from where it will do the read).
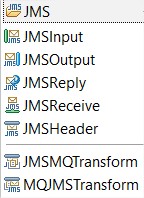
- JMS group: (Java Messaging service, all the nodes are 1.1 and 2.0 compliant, JMS connections are based on JNDI binding connections that can be created from the MQ Explorer tools)
- JMS Input will read any incoming message entering in the queue (can be compared to MQ Input).
- JMS Ouput will write the output message in the target queue (can be compared to MQ Output).
- JMS Reply is similar to JMS Output but can reply to the replyToQueue name (can be compared to MQ Reply).
- JMSReceive will read only one message, the read will often be based on messageID or correlation ID and priority (can be compared to MQ Get).
- JMSHeader has 4 different options, forward the header, add an JMS Header, remove a JMS Header and update JMS Header values (can be compared to MQ Header).
- JMSMQTransform is a node that will transform a message coming from JMS to convert it to an MQ message.
- MQJMSTransform: is a node that will transform a message coming from MQ to convert it to a JMS message.
- HTTP group:
- HTTP Input is a web server message receiver.
- HTTP Reply is a message replier coming from an Http input. The reponse will be done base on the HTTP session id.
- HTTP Request will make an http request (such as a curl) with different options availabled such as HTTP GET (to extract an information from the target server), HEAD (similar to GET but will only ask header information), POST (to send data to insert into the target server), DELETE (to remove the data from the target server), PUT ( to update a data into the target server), PATCH (to apply a partial updated on a data into the target server), OPTION (to ask the communication server with the target server).
- HTTP Header: has 4 different options, forward the header, add an HTTP Header, remove an HTTP Header and update HTTP Header values.
- HTTP Async Request is similar to the HTTP Input witch is a sync node and will release the requestor that will wait for a response later.
- HTTP Async Response is similar to the HTTP Reply which is a sync node and will reply to the async requestor based on the session id.
- REST Request is the node that will send a JSON request to a REST service and wait for the response as a sync node.
- REST Async Request is the node that will send a JSON request to a REST service and not wait for the response as an async node.
- REST Async Response is the node that will wait for a JSON response from a REST service based on a session id as an async node.

- Web Services group:
- SOAP Input is a SOAP web service listener waiting for a SOAP request. This node has two operation modes:
- Specitfy to a WSDL/XSD which will define the contract to respect to call the service.
- As a gateway which is a generic node accepting any valid SOAP request.
- SOAP Reply is a SOAP replied that will send a SOAP reponse based on the http session id.
- SOAP Request is a SOAP client that will send a SOAP request to a SOAP web service.
- SOAP Async Request is similar to the SOAP request as a sync node that will not wait for the response.
- SOAP Async Response will wait for the SOAP async response based on a session id.
- SOAP Envelope is a node that can help create the soap envelope.
- SOAP Extract will retrieve specific requested information the a SOAP envelope to a target variable but also can route the message based on certain conditions.
- Registry Lookup is a node that can retired any entity information for IBM WSRR (Websphere Registry and repository). WSRR is a tool that help register metadata web services but also the WSDL and XSD.
- Endpoint Lookup is similar to Registry Lookup but will retreive endpoint information.
- SOAP Input is a SOAP web service listener waiting for a SOAP request. This node has two operation modes:
- Adapters group:
- PeopleSoft:
- PeopleSoft Input is a node that will wait for compatible requests with the CRM tool PeopleSoft.
- PeopleSoft Request is a node that will send requests with the CRM tool PeopleSoft.
- SAP:
- SAP Input is a node that will wait for compatible requests with the accounting tool SAP.
- SAP Request is a node that will send compatible requests with the accounting tool SAP.
- SAP Reply is a node that will send
- PeopleSoft:
- Adapters group:
- PeopleSoft:
- PeopleSoft Input is a node that will wait for compatible requests with the CRM tool.
- PeopleSoft Request is a node that will compatible send requests with the CRM tool.
- SAP:
- SAP Input is a node that will wait for compatible requests with the accounting tool.
- SAP Request is a node that will send compatible requests with the accounting tool.
- SAP Reply is a node that will send compatible responses with the account tool.
- Siebel:
- Siebel Input is a node that will wait for compatible requests with the CRM tool.
- Siebel Request is a node that will send compatible requests with the CRM tool.
- JDEdwards:
- JDEdwards Input is a node that will wait for compatible requests with the ERP tool.
- JDEdwards Request is a node that will send compatible requests with the ERP tool.
- PeopleSoft:
- Routing group:
- Routing:
- Filter is an ESQ node to route message based on any business logic that will be developer into the ESQL filter node. The results can go to different output terminal wich are TRUE (a condition is respected), FALSE (a condition is not respected), UNKNOWN (a condition does not match iether TRUE or FALSE), FAILURE (technical error).
- Label: A label is a routing point that can be called from an ESQL (with ROUTE TO LABEL LABEL_NAME) or from the node RouteToLabel.
- Publication: is a node that can filter a message and publish it to a topic based on a the condition of a filter.
- RouteToLabel: is a node that will forward the message to the target label, the label name must be located into the LocalEnvironment variable “OutputLocalEnvironment.Destination.RouterList.DestinationData[1].labelName“. You can specify multiple lable in the DestinationData array to forward the message to multiple lables at once.
- Route: is a very usefull node allowing to send messages to next nodes by terminal output. The route node will filter check the route conditition by XPATH expression and will use the output terminal name to send the message to the next node. This node has 3 different terminals by default and has the particularity to allow custom output terminal creation:
- Failure: is case of technical error.
- Default: the message does not match any xpath filter pattern.
- Match: the message matches an xpath filter pattern.
- Aggregation: Belongs to the aggregation eai dessign pattern. All the nodes belonging to Aggregation need a default queue manager. Aggregation sessions will be stored into specific system queues.
- Aggregate Control: is a node that will initiatie the sessions aggregation for the next aggregate requests and reply.
- Aggregate Reply: is the node waiting fo all the responses from a backend to specify to all sub sessions replied with a response or a timeout. After the aggregate reply, the next action will be to loop on an responses to process the aggregation.
- Aggregate Request: is a the node that will initiate a sub sessions for a new request will be made to a backend.
- Collector: is a node that will create collection from different responses messages based on filter patterns. It can also regroup based on number of responses, bases on xpath and timeout.
- Resequence: is a usefull node to reorder message in case of need that some messsages need to be send by a specific order.
- Sequence: is the node that will be used by the resquence node. It will set a sequence number to the messages.
- Groupping: Belongs to the aggregation eai dessign pattern. This node is similiar to aggregation nodes but has the particularity to not need a default queue manager. Those nodes where developed because the product ACE as a standalone integration server can be deployed and installed as a standalone service without queue manager (very important for future microservices integration server instances into containers or without containers). !!! The sessions and sub sessions mechanism needs to be implemented by yourself in ESQL where the aggregation nodes will do it for you with MQ system queues !!!
- Group Scatter: is similar to Aggregate Control and will initiage the sessions aggregation.
- Group Gather: is a node that will mark the management of a response (reply or timeout).
- Group Complete: is similar to Aggredate Reply and will start asynchronously when all the GroupGather will have a responses. From there, the next action will be to loop on an responses to process the aggregation.
- Routing:
- .NET group:
- .NET Input: is a node that will retrieve data from MicrosoftMQ or a file or a DB based on an assembly (DLL). As an entry node, it will initiate the start of a flow.
- Transformation:
- .Net Compute: is a node that will process messages with .net code wrapped in an assembly (DLL). It is based on .net classes and interfaces specific for IIB/ACE for process Input,Output, Environment Variables, LocalEnvironment variables.
- Mapping: is a powerfull visual data mapper (coming from another IBM product call WTX Websphere Transformation Extender). It can work with DFDL, MRM, XML (XSD contract), JSON (JSON Schema or Swagger 2.0 contract).
- XSL Transformation: is node that will execute an XSLT file to a message to process transformations.
- Compute: Is the famous ESQL compute module to process messages for transformation and/or routing.
- Java Compute: is a node that will class a java class wrapped in a Java project. It is based on classes and interfaces specific for IIB/ACE for process Input,Output, Environment Variables, LocalEnvironment variables.
- Construction group:
- Input: is a node to declare the entry of a subflow.
- Output: is a node to declare the exit of a subflow.
- Throw: will send a throw exception to the flow and go recursively to the first failure terminal if linked.
- Trace: is a node to write data to system log, or a local filed or a user trace.
- TryCatch: Will wrapp an error management to process some actions.
- FlowOrder: will allow to process to flow sequentially as a first flow to run and when the first is finished, will run the second flow.
- Passthrough: will alow to version the execution of a flow by a label name.
- Callebale Flow group:
- Callable Input: is an entry node that will begin when the Callable flow receives a request.
- Callable Reply: is an exit node to send the response from the Callable flow.
- Callable Flow Invoke: is the node to invoke a Callable flow so the next node will be the Callable input.
- Callable Flow Async Invoke: similar to Callable Flow invoke, it will send a request asynchronously and now wait for the responses.
- Callable Flow Async Reponse: is the node that will wait for the response based on the session id of the Callable Flow Async Invoke.

- Cloud Connectors group:
- AppConnectRESTRequest: is a node that will communicate with an App Connect REST API project. The REST API project and this node will use a common Swagger 2.0 contract to be compliant each other.
- SalesforceRequest: is a node that will communicate with all the default CRUD SFDC objects operations. It does not allow to call custom SFDC operations, for that, the would be to use a Soap Request or a Rest request node.
- LoopBack Connectors group:
- LoopBackRequest: is the node to send CRUD requests to loopback services (based on NodeJS) through the loopback connector. You can send requests to loopback of multiple DB for instance or create create your own loopback service to consume.
- In a future post, i will show an example on how to configure your connector fron this link https://www.ibm.com/docs/en/app-connect/11.0.0?topic=connectors-installing-loopback-connector and consume the loopback service of MongoDB, see link https://loopback.io/doc/en/lb4/MongoDB-connector.html or create your own loopback service from https://loopback.io/.
- Database group: !!! Each node of this group needs an ODBC DSN entry !!! To install ODBC on linux, see this link https://docs.microsoft.com/en-us/sql/connect/odbc/linux-mac/installing-the-microsoft-odbc-driver-for-sql-server?view=sql-server-ver16.
- Database Input: Similar to a DB cron, this node will wait for events by running the ESQL code of this node on a interval pooling time.
- Database: This node is similar to the Database input but is executed on the continuity of a flow without pooling interval but also needs ESQL code to execute CRUD statements.
- Database Retrieve: This node will help you to retreive data from one or multiple tables and extract to the OutpuRoot message.
- Database Route: Can be compared to the Route node, it will query data into the DB and based on the result, you can send the results to differents output terminals by configuring the Filter expression table propery.
- This node has 4 different terminals by default and has the particularity to allow custom output terminal creation:
- Failure: in case of technical error.
- Default: Default behavior in case of else condition.
- KeyNotFound: The data is not present into DB.
- Match: The data is found into DB and extracted.
- This node has 4 different terminals by default and has the particularity to allow custom output terminal creation:
- File group:
- File Input: This node is a usefull one allow to read a file from
- The local host.
- A FTP or SFTP or FTPS. To configure the ftp service connection, either for it on the FTP property tab of the node, by applying override bar or with an FTP policy. The credentials will be stored with setdbparms command line.
- File Output: Similar to the file input node, it allows to write some content into a file on the local host or on FTP, STFTP, FTPS.
- File Read: This is node will help in the middle of a flow to read the whole content of a file, read a fixed content record, read based on a delimiter, parse a record based on a schema (xsd, dfdl or mdm).
- FTE Input: this is node is specific to only work with IBM MQ File Transfer Edition. This node will require that ACE has a default Queue manager with the FTE feature enabled. It will read a file and will use system queue to store the content file.
- FTE Ouput: is similar to FTE input but will send the file to a target agent waiting for the file to write.
- CD Input: is a node waiting for data from IBM Sterling Connect Direct and will store the data to the local queue manager. The connection to CD will be done with a policy and the credentials will be store with setdbparms command line.
- CD Output: is similar to CD Input but will send data to the CD server.
- File Input: This node is a usefull one allow to read a file from
- Email group:
- Email Input: is a node waiting for any message coming from a POP3 or IMAP server. The credentials will be store with setdbparms command line.
- Email Output: is a node sending data by SMTP protocol. The credentials will be store with setdbparms command line.
- TCPIP group:
- TCPIP Client Input: is a node to receive a request from a distant TCPIP socket client port. You need to specify a host and a port or a TCPIP Server policy.
- TCPIP Client Output: is a node to reply with a response to a distant TCIP socket client.
- TCPIP Client Receive: is a node to send a request to a distant TCPIP socket client and wait to a synchronous reponse.
- TCPIP Server Input: is a node to allow an integration server to become a TCPIP socket server.
- TCPIP Server Output: is a node to respond to a client socket requestor.
- TCPIP Server Receive: is a node to send a request to a distant TCPIP socket server and wait to a synchronous reponse.
- CORBA Group:
- CORBA Request: Similar to COM model, this node allows to send a CORBA request to CORBA service.
- Rules group:
- ODM Rules: ODM (Operational Desicion Management) is a set of business rules written in XML. The ODM service url must be specified or must be configured in an ODM server policy. Each rule or a specific rule can be executed with Xpath. The ODM XML can also be executed by a Java Compute node.
- CICS group:
- CICS Request: is a node to connect to a mainframe by communicating with CICS TG (Transaction gateway). The request can be sent by commearea, fixed lenght of data that will end up into the working storage section of the COBOL CICS application for instance. The request can also be sent by channel, where the link of the CICS application will be made by Container name.
- IMS group:
- IMS Request: IMS is an old hierarchical DB (non RDBM) storing data linked by parents and children. To connect and send a request, you must provide a host, pord and datastore name or a policy IMS Connect.
- Validation group:
- Validate: is a very useful node to validate message of type XMLNS, XMLNSC, SOAP, DFDL, MRM or SAP IDOC. In case of invalid or non compliant data, the validate node will send the exception to the failure terminal.
- Check: is deprecated node. Check will verify that the message complies with a contract and if it is the case, the node will forward the message to the next node, if not, it will not forward the message.
- Security:
- Security PEP: is a very very very useful node to process authentication control. The credentials can be challenged through LDAP, WS-Trust, TFIM (Tivoli Federated Indentify Manager). You can configure the IAM service with the Security Profile.
- Timer group:
- Timeout Control: is a node that will run forward the message to the next node if the time request matches or respects the system clock requirement. The information to check the time is located into an XML. !!!! the node need a local queue manager !!!!
- Timeout Notification: is a node that will behave as a cron. You can specify a timeout internal and each interval reached, the node will start a new theard. !!! This node has two operation modes, automatic where it will not need a local queue manager and will use the timeout interval value to run, controlled mode will get the run information from the local queue manager where a Timeout Control node will give the instruction to the Timeout Notification to run !!!
Timeout Control example:
<TimeoutRequest>
<Action>SET | CANCEL</Action>
<Identifier>String (any alphanumeric string)</Identifier>
<StartDate>String (TODAY | yyyy-mm-dd)</StartDate>
<StartTime>String (NOW | hh:mm:ss)</StartTime>
<Interval>Integer (seconds)</Interval>
<Count>Integer (greater than 0 or -1)</Count>
<IgnoreMissed>TRUE | FALSE</IgnoreMissed>
<AllowOverwrite>TRUE | FALSE</AllowOverwrite>
</TimeoutRequest>This concludes the small explanation of each node of IIB/ACE/CP4I.
I had the chance to use almost 90% of those nodes and i’m a very passionate user of ESBs and see the difference between writting a J2EE service where 100 % of the development must be coded and where only 20 % must be coded on an ESB.