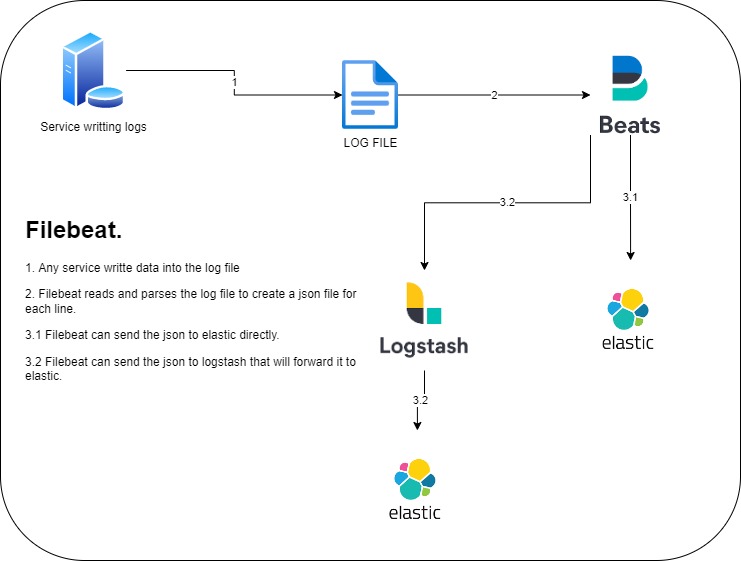
Filebeat usage
In this post, i will explain how filebeat works and what are the possibilities to ingest logs and forward to Elastic/Logstash.
Filebeat is a small application that can be downloaded here : Dowload filebeat.
Either download the .deb file or rpm file for an easy and quick install or the compressed file for Windows, Linux or MacOS.
The application has on its root folder the binary file “filebeat” or “filebeat.exe” and the important configuration file “filbeat.yml“.
There are two ways to configure filebeat and two ways to forward data:
Configuration:
- Configure by modules:
- A Full list of modules can be enabled and are already compatible to parse logs from many different products.
- Filebeat will parse and generate the json message with many different metadata (host, timestamp, log path, …)
- To enable the module here is the command line: “filebeat modules enable MODULE_NAME“
- Example: for IBM MQ : filebeat modules enable ibmmq
- Here is a print screen with an exhaustive list of available modules.
- Configure filebeat manually:
- To be able to configure filebeat, you first need to understand how the log file you want to parse is structured.
- Lets take an example:
[24/Feb/2015:14:06:41 +0530] "GET / HTTP/1.1" 200 11418
[24/Feb/2015:14:06:41 +0530] "GET /tomcat.css HTTP/1.1" 200 5926
[24/Feb/2015:14:06:41 +0530] "GET /favicon.ico HTTP/1.1" 200 21630
[24/Feb/2015:14:06:41 +0530] "GET /tomcat.png HTTP/1.1" 200 5103
[24/Feb/2015:14:06:41 +0530] "GET /bg-nav.png HTTP/1.1" 200 1401...
[24/Feb/2015:14:06:45 +0530] "GET /docs/ HTTP/1.1" 200 19367
[24/Feb/2015:14:06:45 +0530] "GET /docs/images/asf-logo.gif HTTP/1.1" 200 72790:
[24/Feb/2015:14:06:45 +0530] "GET /docs/images/tomcat.gif HTTP/1.1" 200 20660:
[24/Feb/2015:14:06:52 +0530] "GET /docs/logging.html HTTP/1.1" 200 38251
[24/Feb/2015:14:23:58 +0530] "GET /docs/config/valve.html HTTP/1.1" 200 111016
[24/Feb/2015:15:56:41 +0530] "GET /docs/index.html HTTP/1.1" 200 193670:
[24/Feb/2015:15:56:51 +0530] "GET / HTTP/1.1" 200 114180:
[24/Feb/2015:15:57:02 +0530] "GET /manager/html HTTP/1.1" 401 25380:
[24/Feb/2015:15:57:10 +0530] "GET /manager/html HTTP/1.1" 200 158290:
[24/Feb/2015:15:57:10 +0530] "GET /manager/images/tomcat.gif HTTP/1.1" 200 20660:
[24/Feb/2015:15:57:10 +0530] "GET /manager/images/asf-logo.gif HTTP/1.1" 200 7279- Log Analysis:
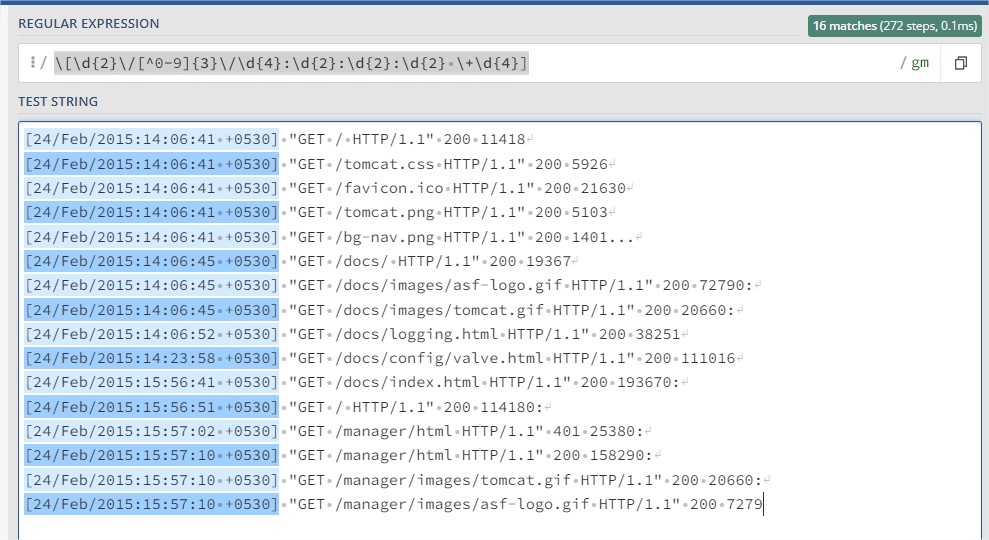
- We can see it this log that it begins with
[TIMESTAMP] - So the purpose will be to create a regex that will recognize the beginning of each line.
- Here is the regex that will match each beginning of lines: [\d{2}\/[^0-9]{3}\/\d{4}:\d{2}:\d{2}:\d{2} +\d{4}]
- We can see it this log that it begins with
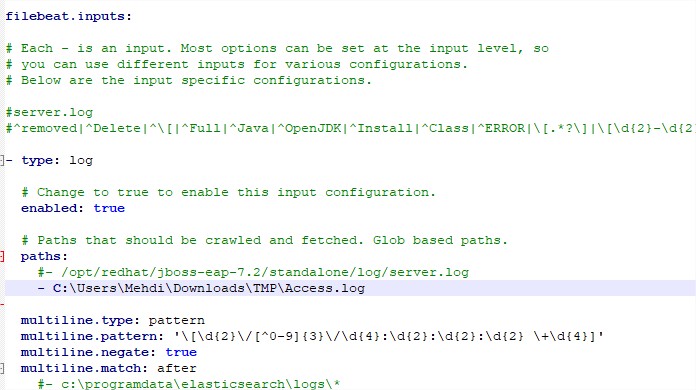
- Configure filebeat:
- Enable the filebeat input section, point to the file path and add the regex into the filebeat.yml configuration file (!!! you can have multiple input streams meaning you can send data from multiple log or steam):
Now you see how to be able to ingest logs with the main options that filebeat offers.
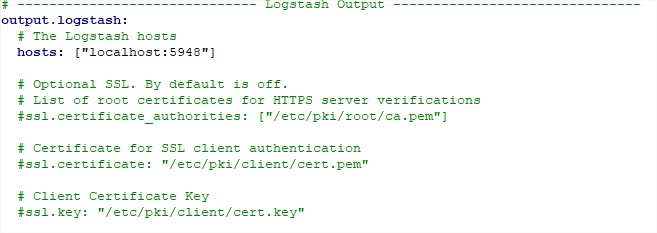
Forward data:
- To forward data, filebeat offfers two options (!!! you can have only ONE output stream meaning you can only have one destination):
- Send to Logstash:
- You send to logstash by http, https, beats, beats over TLS.
- With authentication or anonymously.
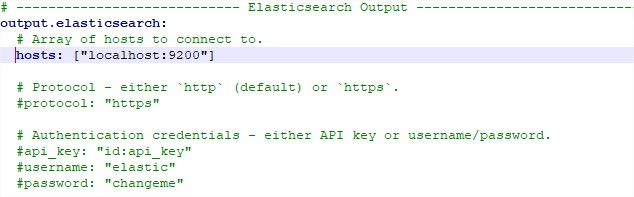
- Send to Elasticsearch:
- You send to elastci by http, https.
- With authentication or anonymously.
- Send to Logstash:
Here is a schema example to propose a point of view of filebeat usage: